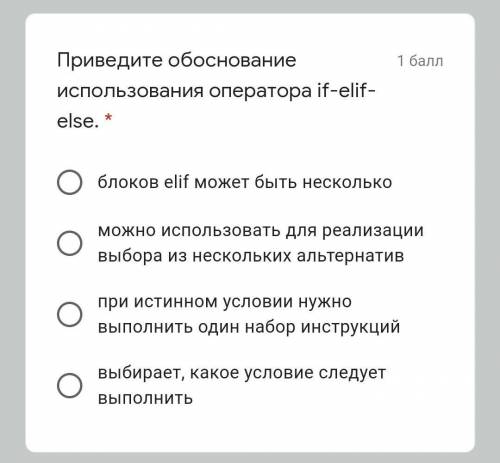
#include <iostream>
#include <regex>
#include <fstream>
#include <string>
using namespace std;
int main() {
ifstream fin("f");
string s = "", _temp;
while (getline(fin, _temp))
s += _temp;
fin.close();
ofstream fout("g");
try {
regex re("[a-z]");
sregex_iterator next(s.begin(), s.end(), re);
sregex_iterator end;
while (next != end) {
smatch match = *next;
fout << match.str();
next++;
}
}
catch (regex_error& e) {
cout << "smth went wrong.";
}
fout.close();
}
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.)[4][5]. Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц[6].
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем[7]. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде)[8].
с инета
можно использовать для реализации выбора из нескольких альтернатив