72 Кб
Объяснение:
1) Определим сколькими битами кодируется отдельный символ, т.е. найдем информационный вес символа.
По формуле 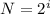 , где N - мощность алфавита, i - информационный вес символа алфавита.
, где N - мощность алфавита, i - информационный вес символа алфавита.
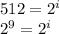
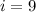 (бит)
(бит)
2) Информационный объем или количество информации находят по формуле 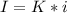 , где K - количество символов, i - информационный вес символов.
, где K - количество символов, i - информационный вес символов.
K = 16*16*256 (симв.) - умножили количество символов на количество строк и получаем количество символов на одной странице, тогда чтобы найти количество символов в книге нужно домножить на количество страниц.
I = 16*16*256*9 = 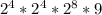 =
= 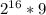 (бит)
(бит)
3) Переведем биты в килобайты, Кб.
1 байт = 8 бит
1 Кб = 1024 байт
1 Кб = 1024 байт = 1024*8 бит = 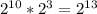 (бит)
(бит)
Тогда для перевода нужно I = разделить на 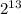 :
:
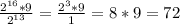 (Кб)
(Кб)
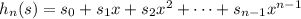 для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)
для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)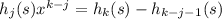 – проверить это быстрее, чем ходить циклом.
– проверить это быстрее, чем ходить циклом.
ну как-то так