В операторах Dat[1] := 7; ... ; Dat[10] := 9; задаются элементы массива. m := 0; n := 0; - начальные значения переменных m и n. В цикле for k := 1 to 10 do ... каждый элемент массива сравнивается с текущим значением переменной m (Dat[k] >= m). Если элемент больше, то значения переменных m и n меняются: в переменной m запоминается значение элемента массива, в переменной n - значение номера (индекс) этого элемента. Таким образом, после выполнения цикла значения переменных будут: m=10; n=8. На экран будет выведено значение 8 (это номер последнего максимального элемента массива). ответ: 8
Можно поступить следующим образом: создаем multimap. Читаем слова из словаря, для каждого слова находим все супрефиксы, вставляем их в multimap в качестве ключа, значение можно ставить любое (например, (int) 1). После этого в цикле читаем слова-образцы и выводим значение count от каждого слова-образца.
Программа будет иметь примерно такую структуру: multimap<string, ...> subprefixes input n n times: input s for j = 0..size of s: if s[..j] is subprefix of s: subprefixes.insert(pair<string, ...>(s[..j], ...)) input m m times: input s print subprefixes.count(s)
Остался вопрос, как определять, является ли s[..j] супрефиксом. Конечно, можно это делать наивно: пройти циклом для всех возможных длин подстрок j и проверить, правда ли, что s[0] = s[s.size() - j - 1], s[1] = s[s.size() - j]...
Как можно ускорить всё это? 1) Выберем какое-нибудь достаточно большое (по сравнению с кодами символов) простое число x, например, x = 1009. Вычислим для строки s все хеши по формуле для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50) Теперь если у строки s длины k есть супрефикс длины j, то обязательно – проверить это быстрее, чем ходить циклом. 2) Необязательно хранить в multimap-е подстроки, это дорого и по времени и по памяти. Можно хранить хеши. 3) Можно вместо одного multimap-а создать 50 multimap-ов, в каждом хранить только супрефиксы одной длины.
Получаем примерно такое: pow = new long long[51] pow[0] = 1 for i = 1..50: pow[i] = x * pow[i - 1] suprefixes = new multimap<long long, ...>[51] input n n times: input s h = hashes(s) k = len s for j = 1..k: if h[j] * pow[k - j] == h[k] - h[k - j - 1]: suprefixes[j].insert(pair(h[j], ...)) input m m times: input s print puprefixes[len s].count(hash(s))
В принципе, для такого решения multimap не нужен, достаточно иметь map, и хранить для каждого ключа количество вхождений. Это можно делать и для multimap.
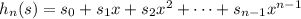 для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)
для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)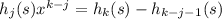 – проверить это быстрее, чем ходить циклом.
– проверить это быстрее, чем ходить циклом.
m := 0; n := 0; - начальные значения переменных m и n.
В цикле for k := 1 to 10 do ... каждый элемент массива сравнивается с текущим значением переменной m (Dat[k] >= m). Если элемент больше, то значения переменных m и n меняются: в переменной m запоминается значение элемента массива, в переменной n - значение номера (индекс) этого элемента. Таким образом, после выполнения цикла значения переменных будут: m=10; n=8. На экран будет выведено значение 8 (это номер последнего максимального элемента массива).
ответ: 8