Дано:
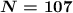 символов (мощность (размер) алфавита)
символов (мощность (размер) алфавита)
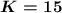 символов (длина сообщения)
символов (длина сообщения)
Найти: 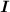 (информац.объём сообщения, кол-во информации в нём)
(информац.объём сообщения, кол-во информации в нём)
Находим количество информации в одном символе.
По сути, это минимальное количество двоичных разрядов, в котором можно хранить один символ нашего алфавита.
Выбирается оно из таблицы степеней двойки (первое значение, не меньшее, чем наше 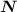 ), либо через формулу
), либо через формулу 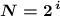 (подбирая минимальное подходящее
(подбирая минимальное подходящее 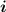 , либо решая уравнение через нахождение двоичного логарифма и затем округляя всегда с избытком, вверх).
, либо решая уравнение через нахождение двоичного логарифма и затем округляя всегда с избытком, вверх).
Пример подбора:
если  , то
, то 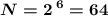 (алфавит из 64 символов можно хранить; для нас мало, надо минимум 107)
(алфавит из 64 символов можно хранить; для нас мало, надо минимум 107)
если  , то
, то 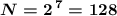 (алфавит из 128 символов можно хранить; для нас достаточно, это даже больше, чем наши 107 символов в алфавите)
(алфавит из 128 символов можно хранить; для нас достаточно, это даже больше, чем наши 107 символов в алфавите)
Выбираем минимальную подходящую степень= 7 (т.е. бит)
Пример расчёта:
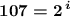
отсюда, получаем что:
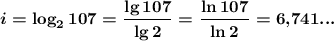
Можно считать одним из трёх : считать сам двоичный логарифм (если логарифм по произвольному основанию есть в вашем калькуляторе- во встроенном в Windows 10, в инженерном виде он есть например), или можно считать отношение десятичных либо натуральных логарифмов (см. дроби в расчёте). Десятичные либо натуральные логарифмы обычно есть в научных калькуляторах.
Получилось дробное значение, значит округляем до целого, но не как обычно, а всегда вверх (то есть, всегда берём целое число, большее чем наш результат). Так округляем потому, что нам нужно получить возможность хранить чуть больше символов, чем есть в нашем алфавите (раз уж ровно 107 не выходит).
Получаем, что: бит
Далее, находим информационный объём сообщения:
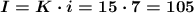 бит
бит
ответ: 105 бит
Відповідь:
#include <iostream>
#include<string>
#include<cmath>
int main() {
setlocale(0,"");
double suma;
int misyac;
std::string s;
while(1){
try{
std::cout<<"Введіть суму вкладу:\n";
std::cin>>s;
suma = std::stod(s);
if(suma<=0) throw 4;/*Помилка від'ємного числа*/
break;
}
catch(int/*Ловимо помилку від'ємного числа'*/){
std::cout<<"Недопустиме значення, повторіть введення.\n";}
catch(.../*Ловимо будь-що*/){
std::cout<<"Невірний ввід, повторіть будь ласка.\n";
}}
while(1){
try{
std::cout<<"Введіть кількість місяців:\n";
std::cin>>s;
misyac = stoi(s);
if(misyac<0) throw 4;
break;
}
catch(int/*Ловимо помилку від'ємного числа*/){
std::cout<<"Недопустиме значення, повторіть введення.\n";}
catch(.../*Ловимо будь-що*/){
std::cout<<"Невірний ввід, повторіть будь ласка.\n";
}}
std::cout<<"За "<<misyac<<" місяців зі сумою вкладу розміром "<<
suma<<" гривень при депозиті у 10% за місяць у вас буде "<<suma*pow(1.1,misyac);
return 0;
}
Стандартная кодировка в Windows - 8 бит на символ.
I = k * i; k = I/i, где I - информационный объем, k - кол-во символов, а i - отводимое количество бит на символ
k = 256 * 8 / 8 = 256 символов
В этом тексте 256 символов. вот так отвечай, потому что ответ нужен такой.