Обычно, для обозначения кол-ва символов используют символ k, но у меня это n, а для объёма информации - I, у меня - V
Для решения данной задачи нужно знать всего две простые формулы:
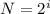 , где N - мощность алфавита (кол-во букв в сообщении),
, где N - мощность алфавита (кол-во букв в сообщении),
i - информационный вес символа
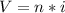 , или более общая формула:
, или более общая формула:
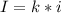 , где k - кол-во символов в сообщении
, где k - кол-во символов в сообщении
I - кол-во информации в тексте (Объём)
А ещё, что 1 байт = 8 бит
Дано: | Решение:
V = 256 байт | 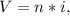
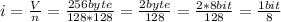
n = 128*128 | ![N = 2^{i} = 2^{\frac{1}{8} } = \sqrt[8]{2}](/tpl/images/1802/6412/d255c.png)
N - ?
ответ: ![\sqrt[8]{2}](/tpl/images/1802/6412/97def.png)
Приведу пример на Haskell.
import Data.List (group, groupBy, sort, sortBy, unfoldr)import Data.Function (on)import System.RandomgetFreq :: [Int] -> [Int]getFreq xs = last $ [[fst zs | zs <- ys] | ys <- groupBy ((==) `on` snd) . sortBy (compare `on` snd) $ [(head x, length x) | x <- group . sort $ xs]]randomList :: Int -> (Int, Int) -> IO [Int]randomList 0 _ = return []randomList n range = do r <- randomRIO range rs <- randomList (n-1) range return (r:rs) main :: (Int, Int) -> IO()main range = do rs <- randomList 20 range print rs print $ getFreq rsЗдесь алгоритм поиска наиболее часто встречающихся чисел последовательности реализован в функции getFreq. В ней мы исходный массив сортируем и группируем соседние элементы по значению. Затем формируем список из кортежей (число, частотность) и сортируем по возрастанию частотности. Затем группируем соседей по частотности, выделяем только значения, без указания частотности и берем последний элемент – самая большая частотность. Этот элемент – список из самых часто встречающихся элементов.

нужно 15 поделить на 7 и получится 2.14285714