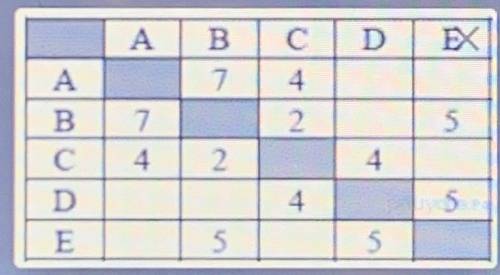
Между населёнными пунктами А, В, С, D, Е построены дороги, протяжённость которых (в километрах) приведена в таблице. Определите длину кратчайшего пути между пунктами А и E. Передвигаться можно только по дорогам, протяжённость которых указана в таблице.
Потому что в ASCII всего 2^8 = 256 символов (обычно это цифры, символы, латиница большие и маленькие буквы, национальный алфавит большие и маленькие буквы)
в юникоде же все сложнее. UTF-16 действительно занимает 16 бит на символ и имеет в себе 2^16 = 65`536 символов, куда помещается множество алфавитов разных языков, в том числе куча иероглифов, которые в ASCII просто не помещались. Описание наборов символов есть на вики
но есть еще и UTF-8 юникодная кодировка которая организована куда сложнее, занимает по 8 бит на символ для латиницы, но дальше идет расширение. Например символы кириллицы занимают уже по 16 бит
в юникоде есть и другие типы кодировок типа UTF-32LE соответственно 32 бита на символ
так что утверждение что "код Unicode-2 байта на символ" вообще говоря сомнительно без уточнения конкретной кодировки.
program pediatr; var h_old, h_new, w_old, w_new: integer; begin write('введите рост ребёнка месяц назад (в см): '); readln(h_old); write('введите рост ребёнка сейчас (в см): '); readln(h_new); write('введите вес ребёнка месяц назад (в г): '); readln(w_old); write('введите рост ребёнка сейчас (в г): '); readln(w_new); if ( (h_new - h_old) >= 3 ) and ( (w_new - w_old) >= 700) then writeln('Ваш ребёнок развивается хорошо') else writeln('Ваш ребёнок меньше нормы'); end.
в юникоде же все сложнее. UTF-16 действительно занимает 16 бит на символ и имеет в себе 2^16 = 65`536 символов, куда помещается множество алфавитов разных языков, в том числе куча иероглифов, которые в ASCII просто не помещались. Описание наборов символов есть на вики
но есть еще и UTF-8 юникодная кодировка которая организована куда сложнее, занимает по 8 бит на символ для латиницы, но дальше идет расширение. Например символы кириллицы занимают уже по 16 бит
в юникоде есть и другие типы кодировок типа UTF-32LE соответственно 32 бита на символ
так что утверждение что "код Unicode-2 байта на символ" вообще говоря сомнительно без уточнения конкретной кодировки.