Так как язык не указан, приведу пример на SWI-Prolog.
Код:
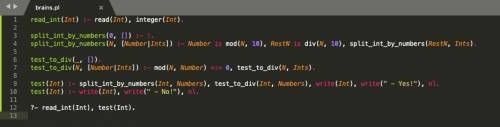
read_int(Int) :- read(Int), integer(Int).split_int_by_numbers(0, []) :- !.split_int_by_numbers(N, [Number|Ints]) :- Number is mod(N, 10), RestN is div(N, 10), split_int_by_numbers(RestN, Ints).test_to_div(_, []).test_to_div(N, [Number|Ints]) :- mod(N, Number) =:= 0, test_to_div(N, Ints). test(Int) :- split_int_by_numbers(Int, Numbers), test_to_div(Int, Numbers), write(Int), write(" - Yes!"), nl.test(Int) :- write(Int), write(" - No!"), nl.?- read_int(Int), test(Int).
Таким образом, оставшиеся три кода не могут быть началом кода буквы Б, и началами кодов друг друга.
То есть коды 0 и 00 отпадают сразу, т.к. это начала буквы Б.
Если предположить, что один из кодов равен 1, и что нам нужны кратчайшие коды, значит оставшиеся коды могут быть только 01 и 011.
Если предположить, что коды двузначны, тогда кодами могут быть 01, 10 и 11.
В первом случае суммарная длина кодов равна 1+2+3+3 = 9, во втором случае - 2+2+2+3 = 9.
Оба варианта подходят, кратчайшая суммарная длина - 9