Все знают эту команду. Но когда данные, которые вы пытаетесь обработать, большие, попробуйте добавить аргумент nrows = 5, чтобы прочитать только крошечную часть таблицы перед фактической загрузкой всей таблицы. Зачем? Так удастся избежать ошибки с выбором неправильного разделителя, ведь это не всегда запятая.
Или используйте head в Linux, чтобы вывести первые, скажем, 5 строк из любого текстового файла: head –n 5 data.txt.
Извлеките список столбцов с df.columns.tolist(). Добавьте аргумент usecols = ['c1', 'c2',…], чтобы загрузить только необходимые столбцы. Кроме того, если знаете типы данных нескольких конкретных столбцов, добавьте аргумент dtype = {'c1': str, 'c2': int,…}. Так загрузка будет быстрее. Этот аргумент даёт ещё одно преимущество. Если один столбец содержит строки и числа, рекомендуется объявить его тип строковым. Так вы избежите ошибок при объединении таблиц, когда используете этот столбец как ключ.
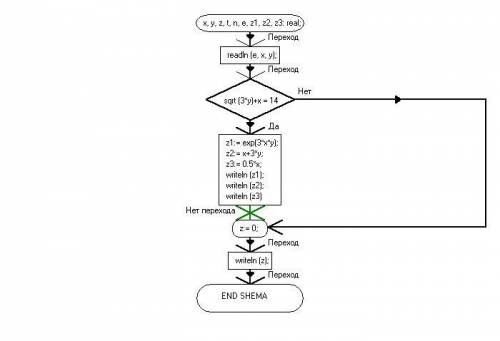
1.
Program u666;
Var
x, y, z, t, n, e, z1, z2, z3: real;
Begin
readln (e, x, y);
if sqrt (3*y)+x = 14
then
begin
z1:= Exp(3*x*y);
z2:= x+3*y;
z3:= 0.5*x;
writeln (z1);
writeln (z2);
writeln (z3)
end
else
z:= 0;
writeln (z);
end.
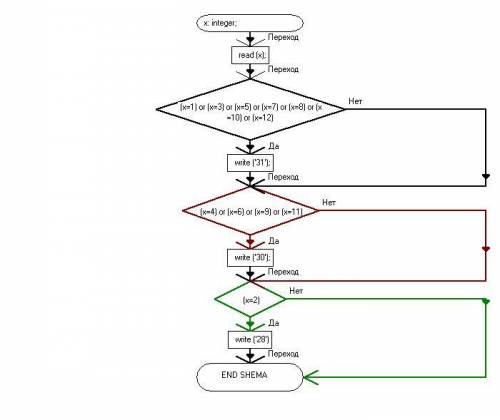
2. Program Regret;
var x: integer;
begin
read (x);
if (x=1) or (x=3) or (x=5) or (x=7) or (x=8) or (x=10) or (x=12)
then write ('31');
if (x=4) or (x=6) or (x=9) or (x=11)
then write ('30');
if (x=2)
then write ('28')
end.
Объяснение:
Интернет урок)

Пятое задание на фотке