n = 0
x = False
print('Вводите числа по очереди')
print('Чтобы закончить введите 100')
while n != 100:
n = int(input())
if not(x) and (n == 77):
x = True
if x:
print('В последовательности есть число 77')
else:
print('В последовательности нету числа 77')
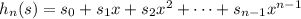 для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)
для n = 1..len s (это делается за линейное время относительно len s, если предпросчитать все степени x от нулевой до 50)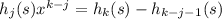 – проверить это быстрее, чем ходить циклом.
– проверить это быстрее, чем ходить циклом.72 Кб
Объяснение:
1) Определим сколькими битами кодируется отдельный символ, т.е. найдем информационный вес символа.
По формуле 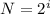 , где N - мощность алфавита, i - информационный вес символа алфавита.
, где N - мощность алфавита, i - информационный вес символа алфавита.
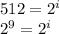
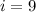 (бит)
(бит)
2) Информационный объем или количество информации находят по формуле 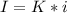 , где K - количество символов, i - информационный вес символов.
, где K - количество символов, i - информационный вес символов.
K = 16*16*256 (симв.) - умножили количество символов на количество строк и получаем количество символов на одной странице, тогда чтобы найти количество символов в книге нужно домножить на количество страниц.
I = 16*16*256*9 = 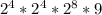 =
= 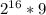 (бит)
(бит)
3) Переведем биты в килобайты, Кб.
1 байт = 8 бит
1 Кб = 1024 байт
1 Кб = 1024 байт = 1024*8 бит = 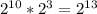 (бит)
(бит)
Тогда для перевода нужно I = разделить на 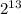 :
:
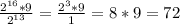 (Кб)
(Кб)
program spos;
uses crt;
var
numb:array [1..100] of byte; // для последовательности чисел
i,f:integer; //счетчик и переменная в качестве флага
begin
randomize;
f:=0;
for i:=1 to 100 do numb[i]:=random(101);// задает последовательность
for i:=1 to 100 do
begin
write(',',numb[i]); // вывод на экран последовательность(можно удалить)
if (numb[i]=77)then f:=1; // в случае удачной проверки f:=1, в противном останется 0
end;
if f=0 then writeln('Yes') else writeln('No');
end.
program spos;
uses crt;
var
numb:array [1..100] of byte; // для последовательности чисел
i,f:integer; //счетчик и переменная в качестве флага
begin
randomize;
f:=0;
for i:=1 to 100 do begin
numb[i]:=random(101);// задает последовательность
write(' ',numb[i]);//вывод на экран, можно удалить
end;
writeln;
i:=0;
repeat
i:=i+1;
if (numb[i]=77)then f:=1; // в случае удачной проверки f:=1, в противном останется 0
until i<100;
if f=0 then writeln('Yes') else writeln('No');
end.