/*Никаких проверок на то что файл не открылся, сломался, удалился и тд. я не делал,
если вам надо - реализуете самостоятельно.*/
#include <iostream>
#include <fstream>
#include <ctime>
int main() {
std::ofstream fin;
std::ifstream fout;
srand(time(NULL));
int N;
std::cin >> N;
int* buff = new int[N];
fin.open("f.txt");
for (int i = 0; i < N; i++) {
fin << rand() % 10 << " ";
}
fin.close();
fout.open("f.txt");
for (int i = 0; i < N; i++)
fout >> buff[i];
fout.close();
fin.open("g.txt");
for (int i = 0; i < N - 1; i++)
fin << buff[i] * buff[i + 1] << " ";
fin.close();
return 0;
}
Объяснение:
выписываешь все уникальные(?) символы, которые есть в предложении.
Аисх = {С, Т, О, И, П, Н, А, К, Е, Л, пробел, запятая};
считаешь их общее количество.
Mисх = 12;
смотрим формулу.
М = 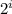 (это та же формула N =
(это та же формула N = 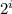 , просто буковки другие, да)
, просто буковки другие, да)
подставляем число 12 под М, но т.к. тут такая непонятная штука со степенью, то подставляем наименьшее целое i, удовлетворяющее следующему неравенству: M <
теперь подставим известное значение мощности исходного алфавита:
12 < , следовательно i = 4(бит). тройка быть не может, т.к. 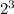 = 8, а 8 < 12.
= 8, а 8 < 12.
теперь каждому символу самостоятельно присваиваешь уникальную кодовую комбинацию. удобнее всего это сделать в виде таблицы. например:
С Т О
0010 1111 0100 и т.д.
теперь пишешь в строчечку все эти комбинации.
001011110100........ не забудь про пробелы и запятые.
чтобы рассчитать объем полученного текстового файла, тебе нужно общее количество символов предложения (34) умножить на 4 бита. это и будем объемом полученного файла.
*если что, то в строчку нужно писать комбинации символов всего предложения, а не только этих 12.
надеюсь, все правильно и понятно.