Тексты вводятся в память компьютера с клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
begin writeln('Сколько тебе лет?:'); readln(b); if b > 17 then begin writeln('В каком институте ты учишься?:'); readln(a); writeln(a, ' хороший институт'); writeln('До следующей встречи!'); end else if b <= 17 then begin writeln('В какой школе ты учишься?'); readln(a); writeln(a, ' не плохая школа'); writeln('До следующей встречи!'); end; end.
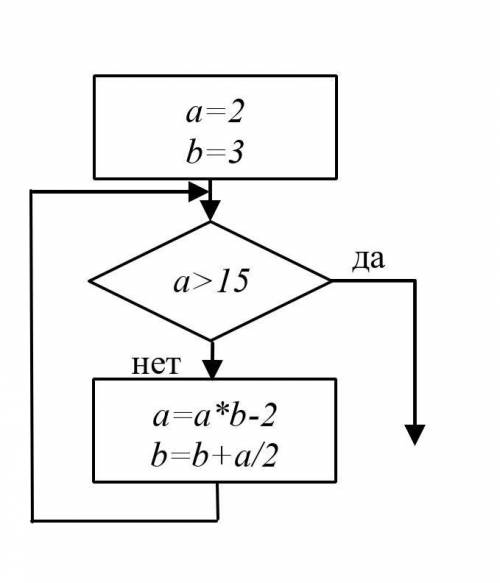
а = а * b – 2 = 2 * 3 – 2 = 6 – 2 = 4
b = b + a/2 = 3 + 4/2 = 3 + 2 = 5
а (4) > 15?а = а * b – 2 = 4 * 5 – 2 = 20 – 2 = 18
b = b + a/2 = 5 + 18/2 = 5 + 9 = 14
ответ: b: = 14..